
【UVM学习笔记】UVM中的“类”
一、UVM派生结构
在上一篇博客讲述了UVM的结构,大家可以发现所有的结构分为两大类,一个是uvm_component,另一个是uvm_object。
uvm_object是UVM中最基本的类,读者能想到的几乎所有的类都继承自uvm_object,包括uvm_component。uvm_component有两大特性是uvm_object所没有的,一是通过在new的时候指定parent参数来形成一种树形的组织结构,二是有phase的自动执行特点。下面是整个UVM类的派生图:
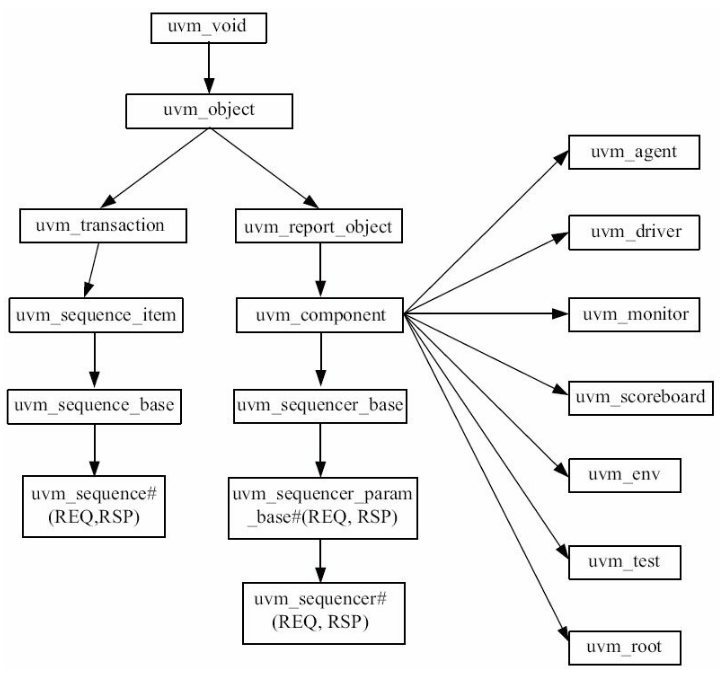
1.1 来自uvm_object的类
既然uvm_object是最基本的类,那么其能力恰恰也是最差的,当然了,其扩展性也是最好的。下面这几个是派生与其的类:
- uvm_sequence_item:之前定义的所有的transaction要从uvm_sequence_item派生。在UVM中,不能从uvm_transaction派生一个transaction,而要从uvm_sequence_item派生。因为uvm_sequence_item是从uvm_transaction派生而来的,因此uvm_sequence_item相比uvm_transaction添加了很多实用的成员变量和函数/任务。
- uvm_sequence:所有的sequence要从uvm_sequence派生。sequence就是sequence_item的组合。
- config:所有的config一般直接从uvm_object派生。config的主要功能就是规范验证平台的行为方式。如规定driver在读取总线时 地址信号要持续几个时钟,片选信号从什么时候开始有效等。但是不要和前面的uvm_config_db搞混了
除了这些,还有一些没有见过的:
- uvm_reg_item派生自uvm_sequence_item,用于register model中。
- uvm_reg_map、uvm_mem、uvm_reg_field、uvm_reg、uvm_reg_file、uvm_reg_block等与寄存器相关的众多的类都是派生自uvm_object,它们都是用于register model。
- uvm_phase派生自uvm_object,其主要作用为控制uvm_component的行为方式,使得uvm_component平滑地在各个不同的phase之间依次运转。
1.2 来自uvm_component的类
这个就是上一篇博客中树的各个部分了。
- uvm_driver:所有的driver都要派生自uvm_driver。driver的功能主要就是向sequencer索要sequence_item,并且将sequence_item里的信息驱动到DUT的端口上。
下面是其成员变量:
1 | uvm_seq_item_pull_port #(REQ, RSP) seq_item_port; |
- uvm_monitor:所有的monitor都要派生自uvm_monitor。monitor做的事情与driver相反,driver向DUT的pin上发送数据,而monitor则是从DUT的pin上接收数据,并且把接收到的数据转换成transaction级别的sequence_item,再把转换后的数据发送给scoreboard。
- uvm_sequencer:所有的sequencer都要派生自uvm_sequencer。sequencer的功能就是组织管理sequence,当driver要求数据时, 它就把sequence生成的sequence_item转发给driver。
- uvm_scoreboard:一般的scoreboard都要派生自uvm_scoreboard。scoreboard的功能就是比较reference model和monitor分别发送来的数据,根据比较结果判断DUT是否正确工作。
- reference model:UVM中并没有针对reference model定义一个类。所以通常来说,reference model都是直接派生自uvm_component。reference model的作用就是模仿DUT,完成与DUT相同的功能。
- uvm_agent:所有的agent要派生自uvm_agent。与前面几个比起来,uvm_agent的作用并不是那么明显。它只是把driver和monitor封装在一起,根据参数值来决定是只实例化monitor还是要同时实例化driver和monitor。
- uvm_env:所有的env(environment的缩写)要派生自uvm_env。env将验证平台上用到的固定不变的component都封装在一起。
- uvm_test:所有的测试用例要派生自uvm_test或其派生类,不同的测试用例之间差异很大,所以从uvm_test派生出来的类各不相同。
二、UVM中打印信息的控制
2.1 冗余度
UVM通过冗余度级别的设置提高了仿真日志的可读性。在打印信息之前,UVM会比较要显示信息的冗余度级别与默认的冗余度阈值,如果小于等于阈值,就会显示,否则不会显示。
默认的冗余度阈值是UVM_MEDIUM,所有低于等于UVM_MEDIUM(如UVM_LOW)的信息都会被打印出来。
2.2 重载
重载是深入到UVM骨子里的一个特性。UVM默认有四种信息严重性:UVM_INFO、UVM_WARNING、UVM_ERROR、 UVM_FATAL。这四种严重性可以互相重载。
2.3 UVM_ERROR到达一定数量结束仿真
当uvm_fatal出现时,表示出现了致命错误,仿真会马上停止。UVM同样支持UVM_ERROR达到一定数量时结束仿真。这个功能非常有用。
实现这个功能的是set_report_max_quit_count函数:
1 | function void base_test::build_phase(uvm_phase phase); |
2.4 UVM的断点功能
在程序调试时,断点功能是非常有用的一个功能。
在程序运行时,预先在某语句处设置一断点。当程序执行到此处时,停止仿真,进入交互模式,从而进行调试。
断点功能需要从仿真器的角度进行设置,不同仿真器的设置方式不同。为了消除这些设置方式的不同,UVM支持内建的断点功能,当执行到断点时,自动停止仿真,进入交互模式:
1 | env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY| UVM_STOP); |
2.5 将输出信息导入文件中
UVM会将UVM_INFO等信息显示在标准输出(终端屏幕)上。各个仿真器提供将显示在标准输出的信息同时输出到一个日志文件中的功能。
1 | virtual function void connect_phase(uvm_phase phase); |
上述代码将env.i_agt.drv的UVM_INFO输出到info.log,UVM_WARNING输出到warning.log,UVM_ERROR输出到error.log, UVM_FATAL输出到fatal.log。
2.5 控制打印信息的行为
有很多宏定义:
1 | typedef enum { |
其中UVM_NO_ACTION是不做任何操作;UVM_DISPLAY是输出到标准输出上;UVM_LOG是输出到日志文件中,它能工作 的前提是设置好了日志文件;UVM_COUNT是作为计数目标;UVM_EXIT是直接退出仿真;UVM_CALL_HOOK是调用一个回调 函数;UVM_STOP是停止仿真,进入命令行交互模式。
三、config_db机制
路径和层次结构是两个不同的概念,如果你使用了下面的代码:
1 | drv = my_driver::type_id::create("driver"); |
这样的话,那么drv在my_casen看来,层次结构依然是env.i_agt.drv,但其路径变为了env.i_agt.driver。在好的编码习惯中,这种变量名与 其实例化时传递的名字不一致的情况应该尽量避免。
3.1 set与get函数的参数
config_db机制用于在UVM验证平台间传递参数。set函数是寄信,而get函数是收信。代码如下:
1 | uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100); |
其中第一个和第二个参数联合起来组成目标路径,与此路径符合的目标才能收信。第一个参数必须是一个uvm_component实例的指针,第二个参数是相对此实例的路径。第三个参数表示一个记号,用以说明这个值是传给目标中的哪个成员的,第四个参数是要设置的值。
在driver中的build_phase使用如下方式收信:
1 | uvm_config_db#(int)::get(this, "", "pre_num", pre_num); |
get函数中的第一个参数和第二个参数联合起来组成路径。
3.2 跨层次的多重设置
假如uvm_test_top和env中都对driver的pre_num的值进行了设置,获得的数值还是uvm_test_top,UVM规定层次越高,那么它的优先级越高。这里的层次指的是在UVM 树中的位置,越靠近根结点uvm_top,则认为其层次越高。
当跨层次来看待问题时,是高层次的set设置优先;当处于同一层次时,上节已经提过,是时间优先。
3.3 非直线的设置与获取
若在其他component,如scoreboard中,对driver的某些变量使用config_db机制进行设置,则称为非直线的设置,我们应该尽量避免这种方式。
总结
本次描述了在上一节定义的众多组件的详细介绍,能够让我们更加深刻的了解UVM各组件之间的协调运转。
 wechat
wechat



